尾递归优化为循环
1、阶乘的尾递归循环
// 递归版本
int factorial(int n, int acc = 1) {
if (n == 0) return acc;
return factorial(n-1, acc * n); // 尾递归
}
// 或者
int factorial(int n) {
if (n == 1) return 1;
return n * factorial(n-1); // 尾递归
}
// 迭代版本
int factorial_iter(int n) {
int acc = 1;
for (int i = 1; i <= n; i++) {
acc *= i;
}
return acc;
}2、斐波那契数列的尾递归循环
// 递归版本
int fibonacci(int n){
if(n <= 1) return n;
return fibonacci(n-1) + fibonacci(n-2); // 尾递归
}
//迭代版本
int fibonacci(int n) {
if (n <= 1) return n;
int a = 0, b = 1, c;
for (int i = 2; i <= n; i++) {
c = a + b;
a = b;
b = c;
}
return b;
}显式栈模拟递归调用栈
恶补函数帧栈
基础
指针字节与计算机位数
内存中的每一个字节都进行了编号,这个编号就是地址,地址的意义在于我们可以快速读取到这个地址上面的数据,编号越大说明这个字节距离初始字节越远,那么阿Q提问:最远的地址有多大呢?
如果是32位系统,主流计算机是二进制的,那么这个系统的最大寻址能力是2^32,就是32位电脑最多支持4G运存,那么最远的地址就是4G运存的最后一位字节,给这个字节编号就是2^32(一般把这个数用16进制表示),为了能表达这个最大的位置数,就需要想办法了。
一个字节有8个比特位,1个比特位只能表达1和0两个数,2个比特位可以表达4个数,要表达2^32个数,就需要32个比特位,也就是4个字节,所以一个指针变量至少需要4个字节才够用。那为什么不用5个字节6个字节呢,浪费内存资源。 (同理 64位系统 指针则需要8个字节)
获取代码区的地址
映射文件 – 查看函数和代码段的精确布局的gcc指令
// powershell
gcc -o test test.c "-Wl,-Map,test.map"__builtin_return_address(n)
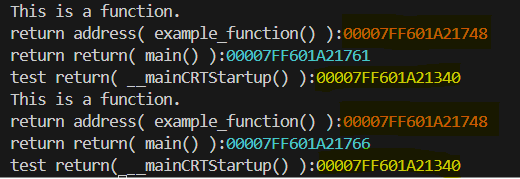
GCC/Clang 的内建函数,用于获取调用栈中第 n 层函数调用的返回地址。
#include <stdio.h>
void f(){
printf("return address( example_function() ):%p\n",__builtin_return_address(0)); // 返回的为调用者 example_function()中 f()代码块地址
printf("return return( main() ):%p\n",__builtin_return_address(1)); // 返回的 为 第二层调用者 main()中 example_function()代码块地址
printf("test return( __mainCRTStartup() ):%p\n",__builtin_return_address(2)); // 返回的为第三层调用者 __mainCRTStartup() 中 main()代码块地址
}
void example_function() {
printf("This is a function.\n");
f();
}
int main() {
example_function();
example_function();
return 0;
}
访问代码段的内容
可以通过函数指针或直接地址(操作系统将代码段标记为可执行(EXECUTE)和可读(READ),但不可写(WRITE))
#include <stdio.h>
#include <stdint.h>
void example_function() {
printf("This is a function.\n");
}
int main() {
// 获取函数地址
uintptr_t func_addr = (uintptr_t)example_function; // 用unsigned __int64指针
printf("函数地址: %p\n", (void*)func_addr);
// 读取前4字节的机器码(x86-64示例)
unsigned char *code = (unsigned char*)func_addr;
printf("机器码: %02x %02x %02x %02x\n", code[0], code[1], code[2], code[3]);
return 0;
}
/*
输出结果:
函数地址: 00007FF606D616D0
机器码: 55 48 89 e5
*/阿Q将两者合在一起看看
#include <stdio.h>
#include <stdint.h>
void f(){
printf("调用example_function() f()块地址:%p\n",__builtin_return_address(0)); // 返回的为调用者 example_function()中 f()代码块地址
printf("调用者main() example_function()块地址:%p\n",__builtin_return_address(1)); // 返回的 为 第二层调用者 main()中 example_function()代码块地址
printf("调用者__mainCRTStartup() main()块地址:%p\n",__builtin_return_address(2)); // 返回的为第三层调用者 __mainCRTStartup() 中 main()代码块地址
}
void example_function() {
printf("This is a function.\n");
f();
}
int main() {
uintptr_t main_addr = (uintptr_t) main;
printf("main函数地址:%p\n",(void*)main_addr);
uintptr_t example_function_address = (uintptr_t)example_function;
printf("example_function函数地址:%p\n",(void*)example_function_address);
uintptr_t f_address = (uintptr_t)f;
printf("f函数地址:%p\n\n",(void*)f_address);
example_function();
example_function();
return 0;
}
在看完函数帧栈后这些地址间有什么意思就能明白了。
寄存器 (汇编)
eax – “累加器”, 它是很多加法乘法指令的缺省寄存器。
ebx – “基地址”寄存器。
esi/edi – “源/目标索引寄存器”, ds:esi – 指向源串; es:edi – 指向目标串
ebp – 基址指针
esp – 栈顶指针,在32位平台,esp每次减少4个字节。
// 汇编
push ebp; // 保存当前ebp
mov ebp, esp; // ebp 设为当前栈底指针
sub esp,xxx; 预留xxx 字节给函数 函数帧栈
阿Q推荐先看大佬的这篇文章函数栈帧(涉及汇编)。
帧栈
维护函数帧栈的两个寄存器(存的是地址哦)
寄存器 ebp:栈底指针 (高地址)
寄存器 esp:栈顶指针 (低地址)
阿Q特别说明函数的栈区使用是从高地址向低地址的。
阿Q:不同编译环境,不同平台的栈帧操作可能有差异,掌握其思想即可。
阿Q将手绘下面代码如何创建函数栈帧的,具体过程包括汇编方面还得看大佬的文章。
#include <stdio.h>
int Add(int x, int y)
{
int z = 0;
z = x + y;
return z;
}
int main()
{
int a = 10;
int b = 20;
int c = 0;
c = Add(a, b);
return 0;
}压栈过程
调用main之前
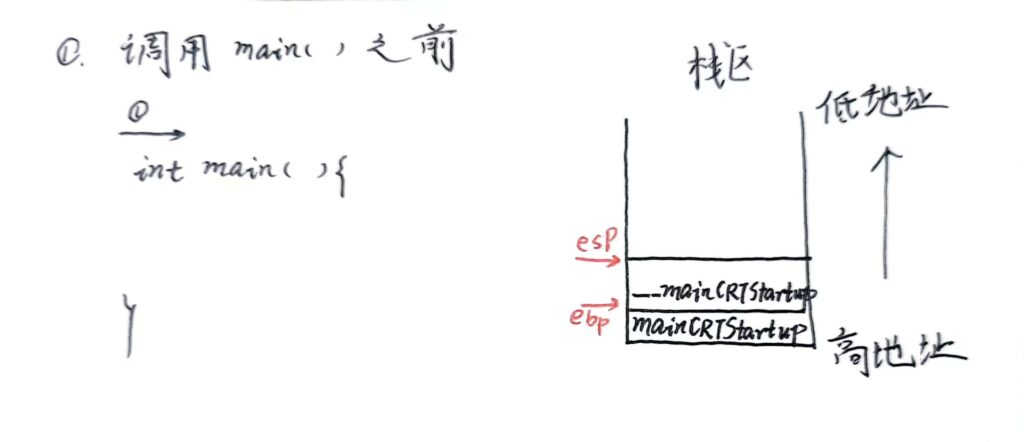
进入main
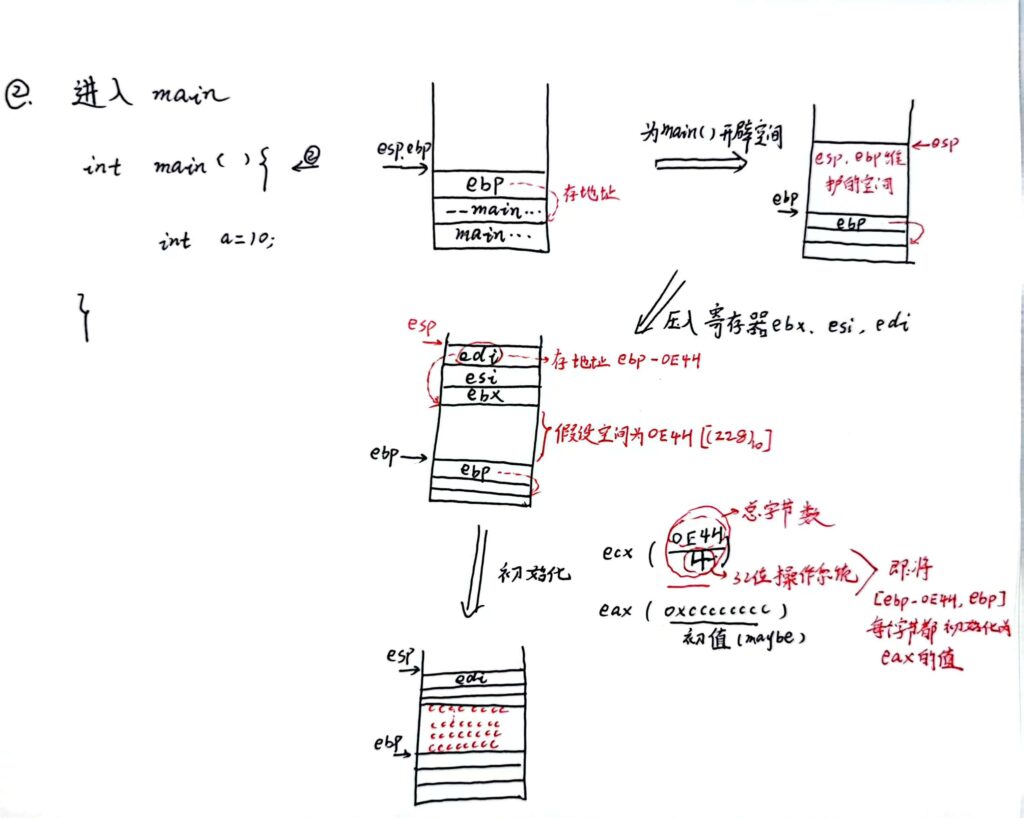
局部变量
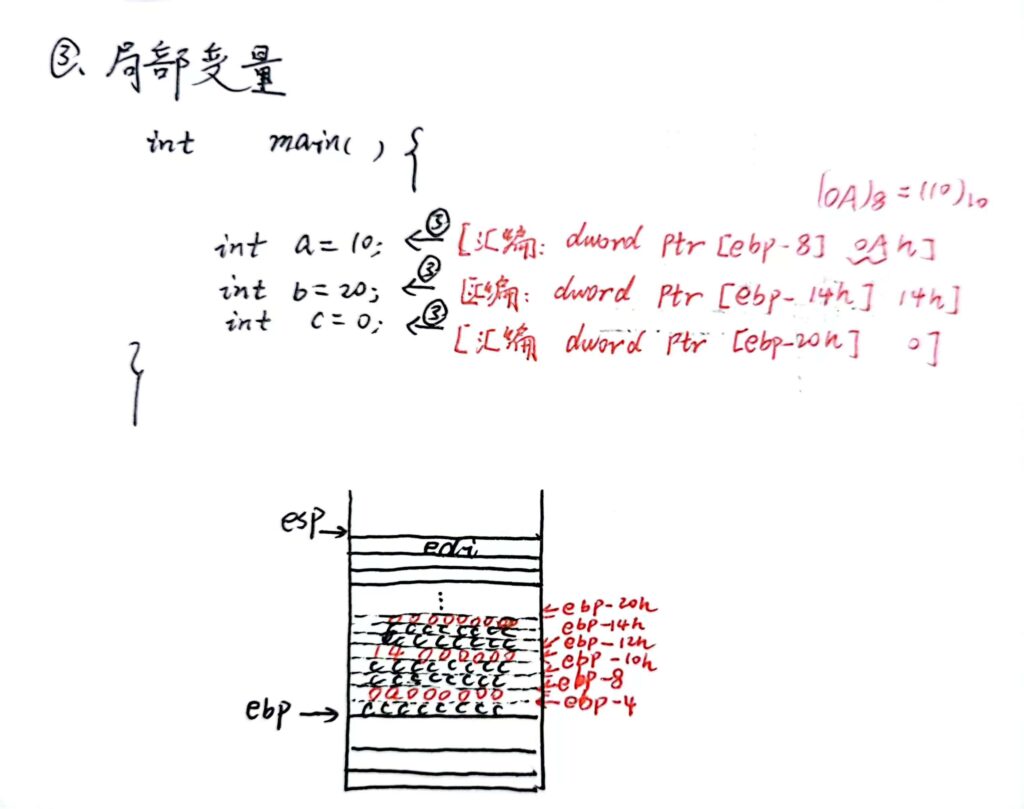
函数被调用(进入被调函数前)
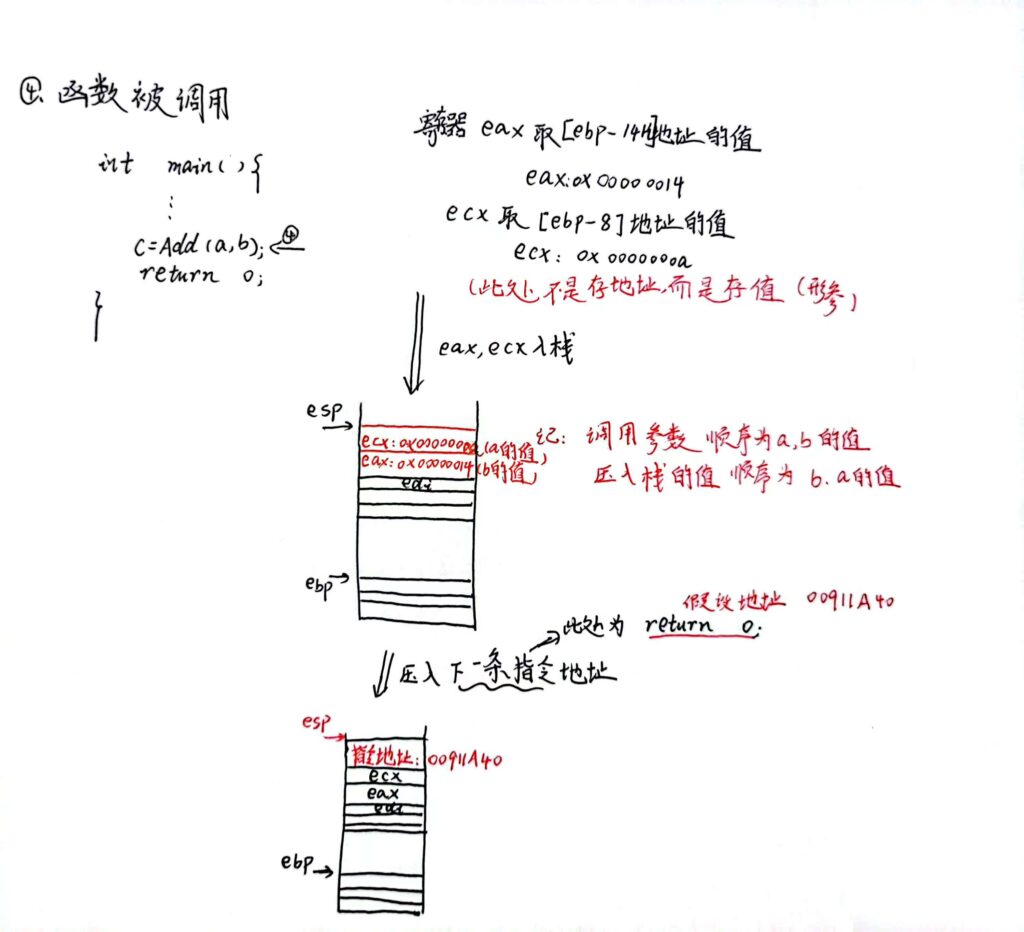
进入被调函数

压栈小结
之后的局部变量操作是一样的,整个最终入栈的情况如下:
#include <stdio.h>
int Add(int x, int y)
{
int z = 0;
z = x + y;
return z;
}
int main()
{
int a = 10;
int b = 20;
int c = 0;
c = Add(a, b);
return 0;
}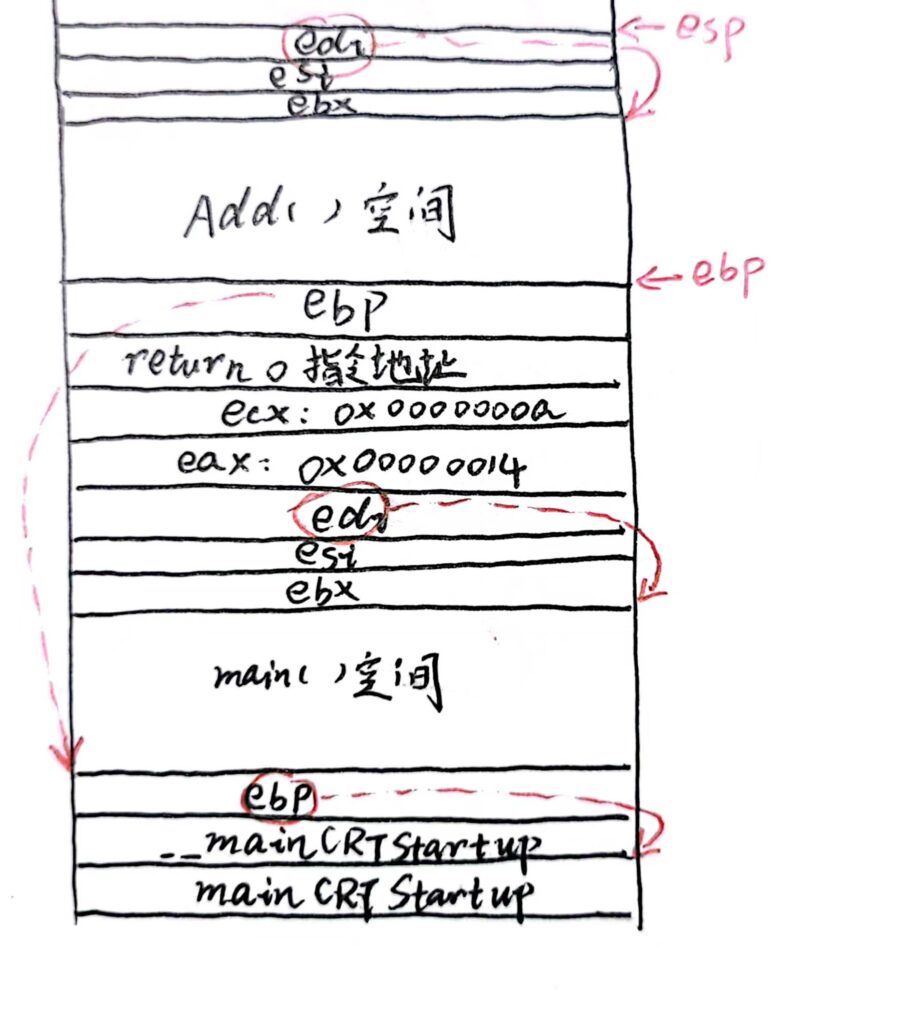
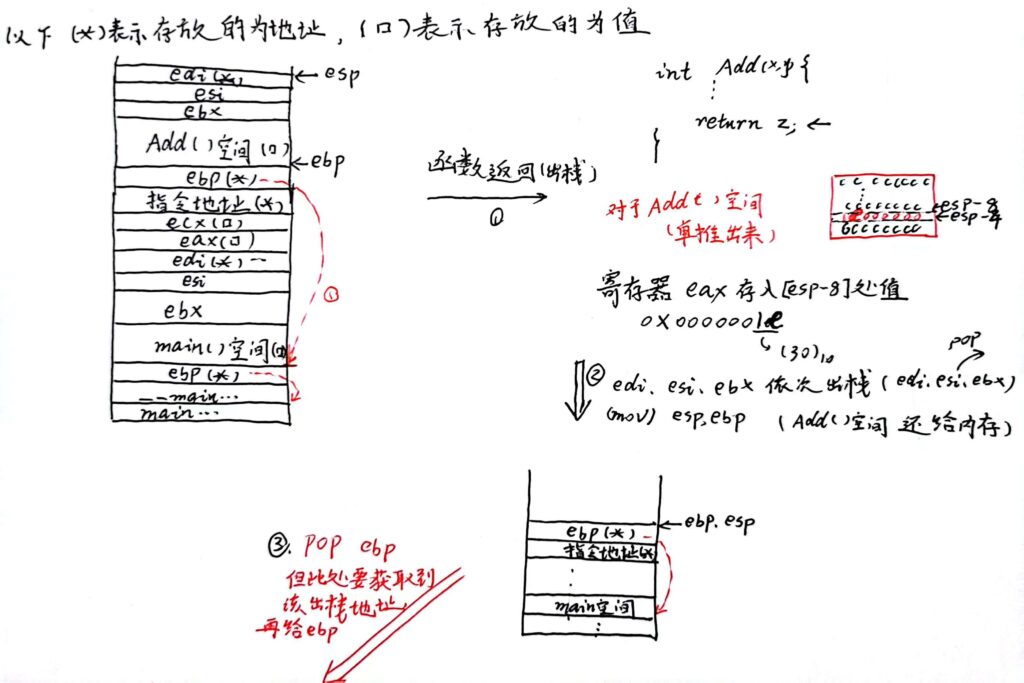
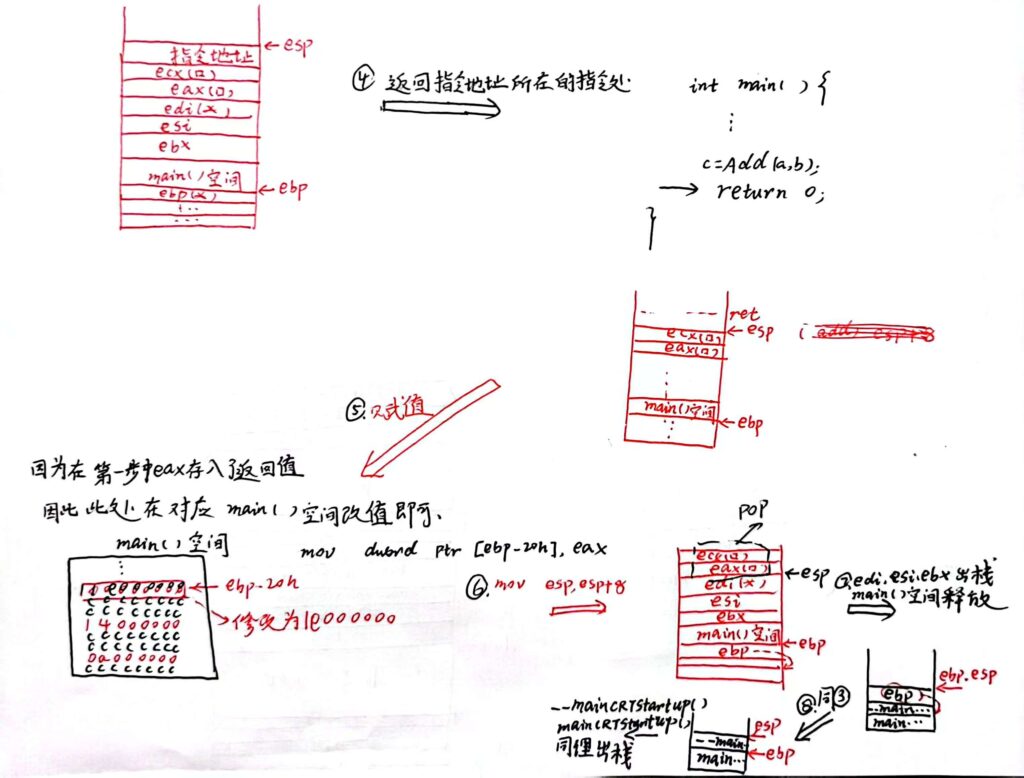
出栈过程
小结
阿Q:整个过程中的 ebp 指针的动态变化太有思想了!
ebp在每次进入新的函数栈域都会首先压入存有原来ebp所在的地址(能保证回退过程中退回到上一层的函数栈域)。
在进入函数前,esp朝低地址前进n个空间(开辟空间),与此时ebp 管理当前函数栈帧。同时给当前函数空间附初值。进入函数后碰到局部变量,则在函数空间中修改某处 如 ebp-8 的值(保存局部变量)。如果该函数调用了某个函数F,则ebp就需要维护F的栈底。(同样首先压入当前ebp所在的地址,ebp再进行移动)
调用函数时(在进入被调函数之前),栈中压入有以下内容(*):
1、值传递时,压入实参的值,而非地址(即:传入形参);指针传递或者引用传递,则压入的是实参的地址。 (从入栈角度考虑)
2、调用函数下一条指令的地址 (从出栈角度考虑)
3、当前的ebp的地址 (从出栈角度考虑)
以上均为阿Q自己的思考,若有问题,请大佬们指出。
显式栈模拟方法
阿Q下面直接使用stack库。
函数帧栈思想
阿Q建议不要用软件去真的模拟系统函数栈(虽然这是通用方法),模拟过程的压栈和出栈性能还不如递归过程。
主要是函数栈的思想,对不同的算法题作针对性的模拟即可。
如:二叉树遍历的非递归算法。
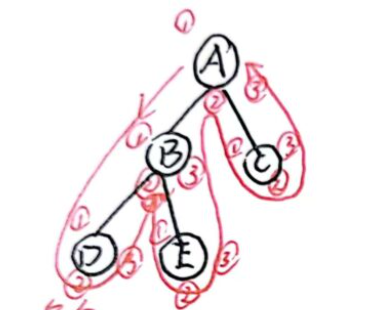
二叉树遍历非递归算法中,阿Q为什么将结点压栈和出栈就能实现非递归算法呢?
看小结(*)部分,根结点满足这些内容嘛?
1、结点存有左右子树,可以压入左右子树的地址。 (指针传递)
2、结点出栈后,函数就接着运行下一条指令(即:不需要压入下一条指令的地址)。
3、结点出栈后,ebp返回到上一个ebp(当前结点 – 当前ebp -> 双亲结点 – 上一个ebp的地址),满足。
void inorderTraversal(Btree root) {
std::stack<BtNode*> stk;
Btree curr = root;
while (curr || !stk.empty()) {
// 模拟递归左子树
while (curr) {
stk.push(curr);
curr = curr->lchild;
}
// 处理当前节点
curr = stk.top();
stk.pop();
std::cout << curr->data << " ";
// 转向右子树(这一步无需加条件的 - 中序遍历)
curr = curr->rchild;
}
}通用转换类型
1、定义帧结构
递归的每一步调用会保存当前参数、局部变量和执行位置。需要将这些信息封装成一个结构体(或类),作为栈帧(Stack Frame)存入显式栈中。
struct StackFrame {
int n; // 递归参数(例如阶乘的n)
int result; // 局部变量(例如当前计算结果)
int stage; // 执行阶段(标记当前执行到递归的哪一步)
// 其他必要的参数和局部变量...
};2、初始化栈
初始参数入栈,模拟递归的第一次调用
stack<StackFrame> stk;
stk.push({n, 0, 0}); // 初始化参数为n,stage标记为0(起始阶段)3、循环处理栈帧
通过循环逐步处理栈顶帧,模拟递归的展开和回溯。
while (!stk.empty()) {
StackFrame& frame = stk.top(); // 获取当前栈顶帧,引用可以修改原有地址内的值
switch (frame.stage) {
case 0: // 阶段0:处理递归的第一步操作
if (递归终止条件) {
// 直接计算并保存结果,模拟递归返回
frame.result = ...;
stk.pop();
// 若需要返回结果,则将结果传回
stk.top().result = frame.result;
} else {
// 标记当前执行阶段(例如即将处理子问题)
frame.stage = 1;
// 压入子问题(模拟递归调用)
stk.push({子问题参数, 0, 0});
}
break;
case 1: // 阶段1:处理子问题返回后的操作
// 使用子问题的结果(frame.result或其他子帧结果)
frame.result = ...;
stk.pop(); // 当前帧处理完毕
// 若需要返回结果, 将结果传回
stk.top().result = frame.result;
break;
// 更多阶段(复杂递归需要多个阶段)
}
}4、处理多阶段递归
若递归中存在多个子调用(如二叉树遍历中的左、右子树),需通过 stage 标记区分处理顺序。
case 0: // 处理左子树前
frame.stage = 1;
stk.push({left_child, ...});
break;
case 1: // 左子树返回后处理当前节点
process_current_node();
frame.stage = 2;
stk.push({right_child, ...});
break;
case 2: // 右子树返回后收尾
stk.pop();
break;实例操作
int factorial(int n) {
if (n == 0) return 1;
return n * factorial(n - 1);
}显示栈实现
// 栈帧中有:当前值、当前返回的结果、问题状态
struct StackFrame {
int n;
int result;
int stage; // 0:未处理子问题, 1:子问题已返回
};
int factorial_iter(int n) {
std::stack<StackFrame> stk;
stk.push({n, 0, 0}); // 初始帧
int final_result = 0;
while (!stk.empty()) {
StackFrame& frame = stk.top();
switch (frame.stage) {
case 0:
if (frame.n == 1) {
// 终止条件,返回1
frame.result = 1;
stk.pop();
if (stk.empty()) final_result = frame.result;
// 将结果传回
else stk.top().result = frame.result;
} else {
// 标记阶段1,压入子问题 n-1
frame.stage = 1;
stk.push({frame.n - 1, 0, 0});
}
break;
case 1:
// 子问题已返回,计算当前结果
frame.result = frame.n * stk.top().result;
stk.pop();
if (stk.empty()) {
final_result = frame.result;
}
// 将结果传回
else stk.top().result = frame.result;
break;
}
}
return final_result;
}阿Q:能否用该方法实现二叉树的前、中、后序遍历?
在DeepSeek-R1的帮助下,阿Q兴奋的晚上睡不着觉,连夜赶完这部分内容。
#include <iostream>
#include <stack>
typedef char TElemtype;
struct TreeNode {
TElemtype val;
TreeNode* left;
TreeNode* right;
TreeNode(int x) : val(x), left(nullptr), right(nullptr) {} // 这种创建树的方法太叼了!
};
// 栈帧有:树结点、当前经过结点的阶段,由于Traverse函数不返回值,因此不需要存 返回值。
struct StackFrame
{
/* data */
std::pair<TreeNode*,int> NodeState; // template<class T1, class T2> Struct pair
// 0 - 第一次经过; 1 - 第二次经过; 2 - 第三次经过
};
void operate(TreeNode* Node)
{
std::cout << Node->val << " ";
}
enum TraversalType {PREODER, INORDER, POSTORDER};
// 重点
void Traversal(TreeNode* root,TraversalType type=PREODER) {
// 使用栈保存节点及其处理阶段
std::stack<StackFrame> stk;
stk.push({{root,0}}); // 初始压入根节点,阶段0
while (!stk.empty()) {
auto& [node, stage] = stk.top().NodeState;
if (!node) {
stk.pop(); // 弹出空节点
continue;
}
switch (stage) {
case 0:
// 阶段0:处理左子树
if(type == PREODER) operate(node);
stk.top().NodeState.second = 1; // 标记为阶段1
if (node->left) {
stk.push({{node->left, 0}}); // 压入左子节点
}
break;
case 1:
// 阶段1:访问当前节点
// 操作
if(type == INORDER) operate(node);
stk.top().NodeState.second = 2; // 标记为阶段2
if (node->right) {
stk.push({{node->right, 0}}); // 压入右子节点
}
break;
case 2:
// 阶段2:完成,弹出节点
// 终止条件
if(type == POSTORDER) operate(node);
stk.pop();
break;
}
}
}
int main() {
// 示例树:1(2(4,5),3)
TreeNode* root = new TreeNode('A');
root->left = new TreeNode('B');
root->right = new TreeNode('C');
root->left->left = new TreeNode('D');
root->left->right = new TreeNode('E');
std::cout << "PreOrder: ";
Traversal(root,PREODER); // 输出:ABDEC
std::cout << std::endl;
std::cout << " InOrder: ";
Traversal(root,INORDER); // 输出:DBEAC
std::cout << std::endl;
std::cout << "PostOrder: ";
Traversal(root,POSTORDER); // 输出:DEBCA
std::cout << std::endl;
return 0;
}
/*
输出结果:
PreOrder: A B D E C
InOrder: D B E A C
PostOrder: D E B C A
*/
总结
对于尾递归,一般就不用显示栈了,太麻烦。
对于非递归模拟栈中结点压入栈就能包含以下内容的情况:1、传参;2、返回下一条指令地址;3、结点自带地址,容易维护ebp,建议使用函数栈帧的思想,而不是用软件真的模拟函数栈帧。
对于递归转非递归不容易做到的情况,使用显示模拟栈,此方法虽然可能减少了内存占用,但是栈操作可能比递归略慢。(看使用场景)
评论