哈夫曼树通过两个权值小的树合并而来,因此仅有度为0的叶子结点和度为2的分支结点。
哈夫曼树:叶子结点 – n个; 度为2的分支结点 – n-1 个;总结点数:2n – 1个
顺序存储
存储类型表示
已知 n个叶子结点,则需要 2n 的数组(0号位不存)去存哈夫曼树
用一维数组结构存储,如图:
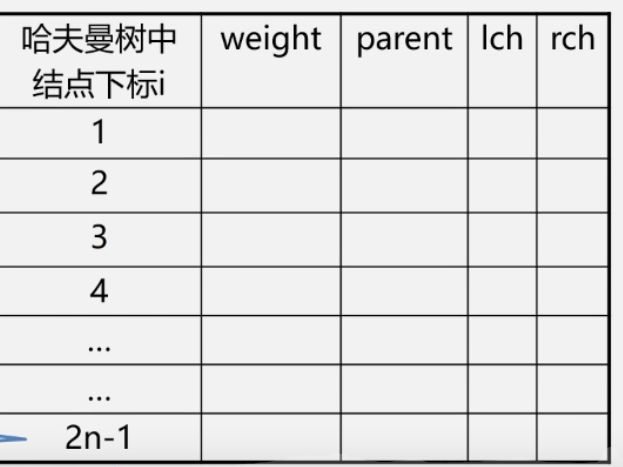
结点数据成员 weight + parent + lch + rch
// 结点
typedef int WeightType; // float、double、..
typedef struct
{
/* data */
WeightType weight;
int parent;
int lchild;
int rchild;
// 可能存其他的数据
// char c;
}HNode;// 一维结构数组
typedef struct
{
/* data */
HNode *Nodes; // 动态分配
int n; // 记录叶子结点树,分配 Htree.Nodes = new HNode[2 * n]
//int r; // 记录根结点下标
}Htree;构造过程
初始化 + 构造哈夫曼树,如图:

// 初始化
void InitHuffmanTree(Htree &T, int weight[], int n){
T.n = n;
T.Nodes = new HNode[2*n];
for(int i = 1; i < 2*n; i++){
T.Nodes[i].weight = 0;
T.Nodes[i].lchild = 0;
T.Nodes[i].rchild = 0;
T.Nodes[i].parent = 0;
}
for(int i = 1; i <= n; i++)
T.Nodes[i].weight = weight[i-1];
// 或者直接输入权值(不传weight数组)
// cin >> T.Nodes[i].weight;
// 若结点内有数据成员 c,则需要传参 char c[]
// T.Nodes[i].c = c[i-1];
}
// 找到最小的两个权值的下标(注意:从 parent == 0中找 - 未组成新树)
// 查找可自行完成 - 阿Q用了最笨的办法
void FindSmall(Htree T, int rlimit, int &fir_small, int &sec_small){
fir_small = sec_small = -1;
// 先找一遍最小值
for(int i = 1; i < rlimit; i++){
// 若已组成新树
if(T.Nodes[i].parent) continue;
if(fir_small < 0) fir_small = i;
else if(T.Nodes[i].weight < T.Nodes[fir_small].weight) fir_small = i;
}
// 再找一遍倒数第二大的
for(int i = 1; i < rlimit; i++){
if(T.Nodes[i].parent || i == fir_small) continue;
if(sec_small < 0) sec_small = i;
else if(T.Nodes[i].weight < T.Nodes[sec_small].weight) sec_small = i;
}
}
// 构造过程
void CreateHuffmanTree(Htree &T){
int fir_small, sec_small;
for(int i = T.n+1; i < 2*T.n; i++){
// 找到最小的两个权值的下标
FindSmall(T, i, fir_small, sec_small);
// 组新树
T.Nodes[fir_small].parent = i;
T.Nodes[sec_small].parent = i;
T.Nodes[i].lchild = fir_small;
T.Nodes[i].rchild = sec_small;
T.Nodes[i].weight = T.Nodes[fir_small].weight + T.Nodes[sec_small].weight;
}
}测试代码
#include<iostream>
#include"HuffmanTree.h"
#define n 4
int main(){
int weight[n] = {7, 5, 2, 4};
Htree T;
InitHuffmanTree(T, weight, n);
CreateHuffmanTree(T);
int wpl = 0;
// 打印数组
std::cout << "index\tWeight\tParent\tlchild\trchild\t" << std::endl;
for(int i = 1; i < 2*n; i++){
std::cout << i << "\t" << T.Nodes[i].weight << "\t" << T.Nodes[i].parent << "\t" << T.Nodes[i].lchild << "\t" << T.Nodes[i].rchild << std::endl;
wpl += T.Nodes[i].weight;
}
wpl -= T.Nodes[2*n-1].weight;
// 打印哈夫曼树的带权路径长度
std::cout << "\tWPL = " << wpl;
return 0;
}
/*
输出结果:
index Weight Parent lchild rchild
1 7 7 0 0
2 5 6 0 0
3 2 5 0 0
4 4 5 0 0
5 6 6 3 4
6 11 7 2 5
7 18 0 1 6
WPL = 35
*/链式存储
哈夫曼树是二叉树,因此当然可以使用二叉链表存储咯
构造过程
阿Q用优先队列去快速解决构造问题 (哈夫曼树概念及构造算法题给阿Q的启示)
#include<queue>
#include<vector>
typedef struct HNode
{
/* data */
// char c;
int weight;
struct HNode *lchild, *rchild;
}HNode, *Htree;
// 定义自定义比较器
struct CompareHNode {
bool operator()(const HNode* a, const HNode* b) const {
return a->weight > b->weight; // 小顶堆(升序排列,队首最小); 比较器的返回值直接控制元素的排列顺序,但它的语义是“谁应该排在后面”
// 若需要大顶堆,改为 a->weight < b->weight
}
};
typedef std::priority_queue<HNode*, std::vector<HNode*>, CompareHNode> Prior_Queue;
// 初始化
void InitHuffmanTree(Prior_Queue &q, int weight[], int n){
// 构造森林全是树
for(int i = 0; i < n; i++){
HNode *node = new HNode;
node->weight = weight[i];
node->lchild = nullptr;
node->rchild = nullptr;
// 结点若有数据成员 c,则需要传参 char c[]
// node->c = c[i];
q.push(node);
}
}
// 构造过程
Htree CreateHuffmanTree(Prior_Queue &q){
HNode *fir_small, *sec_small;
while(q.size() > 1){
// 选用两小造新树,删除两小添新树
fir_small = q.top();
q.pop();
sec_small = q.top();
q.pop();
HNode *newNode = new HNode;
newNode->weight = fir_small->weight + sec_small->weight;
newNode->lchild = fir_small;
newNode->rchild = sec_small;
q.push(newNode);
}
// 返回根结点
Htree Root = q.top();
return Root;
}小结
哈夫曼树是特殊二叉树,是带权路径长度最短的二叉树。
主要关注于 如何创建出哈夫曼树即可。